
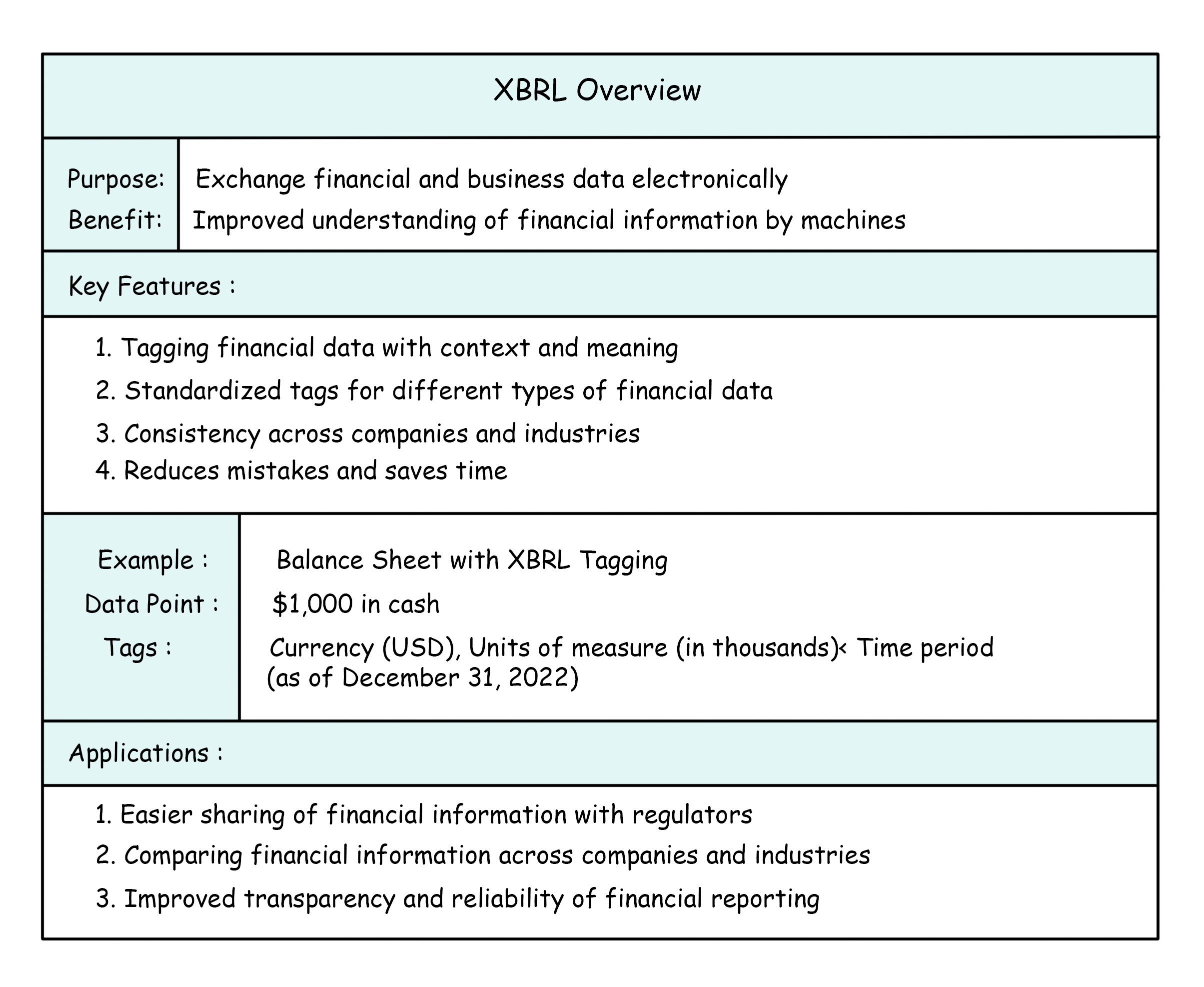
XBRL is a way to exchange financial and business data electronically between different systems.
It's like a language that helps machines understand financial information better. This makes it easier for companies to share their financial information with regulators, and for analysts to compare financial information from different companies and industries.
To help understand this further, let's use an example of a spreadsheet containing financial data such as revenues, expenses, assets, and liabilities. Each number in the table is like a piece of a puzzle, and by itself, it may not make much sense. But with XBRL, each number is tagged with information that gives it context and meaning, allowing it to be easily understood and analyzed.
For instance, consider a company's balance sheet. The balance sheet contains financial data such as assets, liabilities, and equity. Each data point in the balance sheet represents a piece of the financial puzzle, and to fully understand the data, it requires context and meaning. With XBRL tagging, each data point is identified separately and given relevant information, such as the currency, units of measure, and the time period it pertains to.
For example, let's say a company reports $1,000 in cash on its balance sheet. With XBRL tagging, this data point could be tagged with additional information such as the currency (USD), units of measure (in thousands), and the time period it pertains to (as of December 31, 2022). By tagging the data point with this information, it becomes easily understood and analyzed, making it comparable to other companies in the industry and providing valuable insights for businesses, investors, and financial analysts.
XBRL uses standardized tags for different types of financial data, which makes it more reliable and reduces mistakes. It also saves time by automating many of the manual steps involved in preparing and submitting financial statements.
These tags are designed to be consistent across all companies and industries, making it easier to compare and analyze financial data. For example, a company might refer to its sales as "net sales," while another company might refer to it as "revenue."
With XBRL, both of these terms can be tagged with a standardized tag for revenue, making it easier to identify and analyze this type of financial data regardless of the specific terminology used by each company. This ensures that financial data is accurately interpreted and can be compared across different companies, reducing the risk of errors and improving the reliability of financial reporting.
In summary, XBRL is a great tool for anyone who works with financial data. It helps improve transparency, reduce errors, and make financial reporting processes more efficient.
XML is a computer language that helps people store and organize data, kind of like how you organize your things in your room. Each piece of data is labeled with a tag, which tells us what kind of data it is, like a name or a date. These tags can also have extra information, like attributes, that provide more details about the data.
Using XML makes it easier to store and retrieve data because it's organized in a way that makes sense. Just like how you can find something easily in your room because it's labeled and in a specific place, you can find data easily with XML because it's labeled and organized in a specific way.
One cool thing about XML is that it's really flexible. This means people can create their own tags and structures to organize their data in the way that works best for them. It's like making your own labels to organize your things in your room!
Here is an example of an XML Document
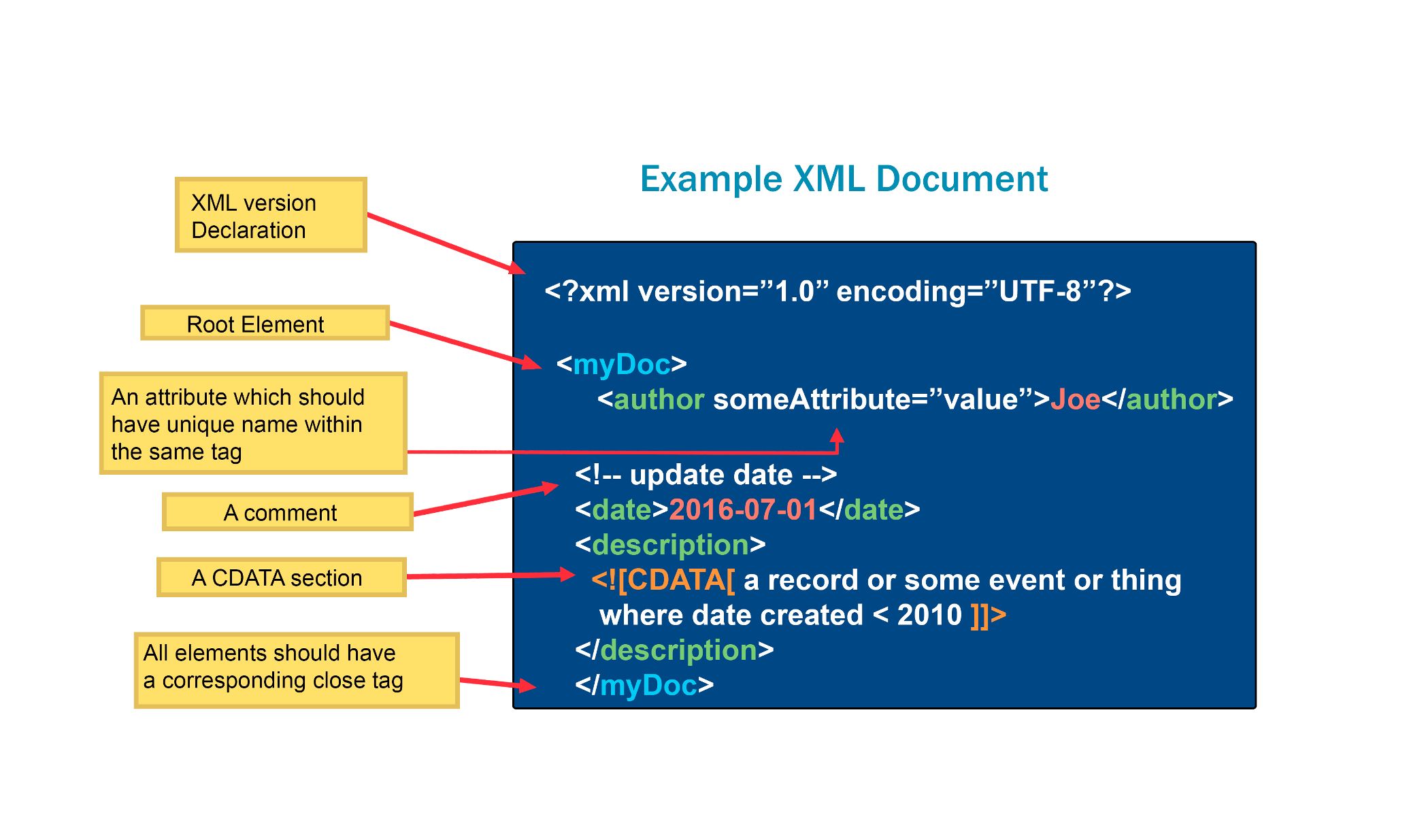
Overall, XML is a powerful tool for managing data, but it's important to choose the right tool for each project.
They contain:
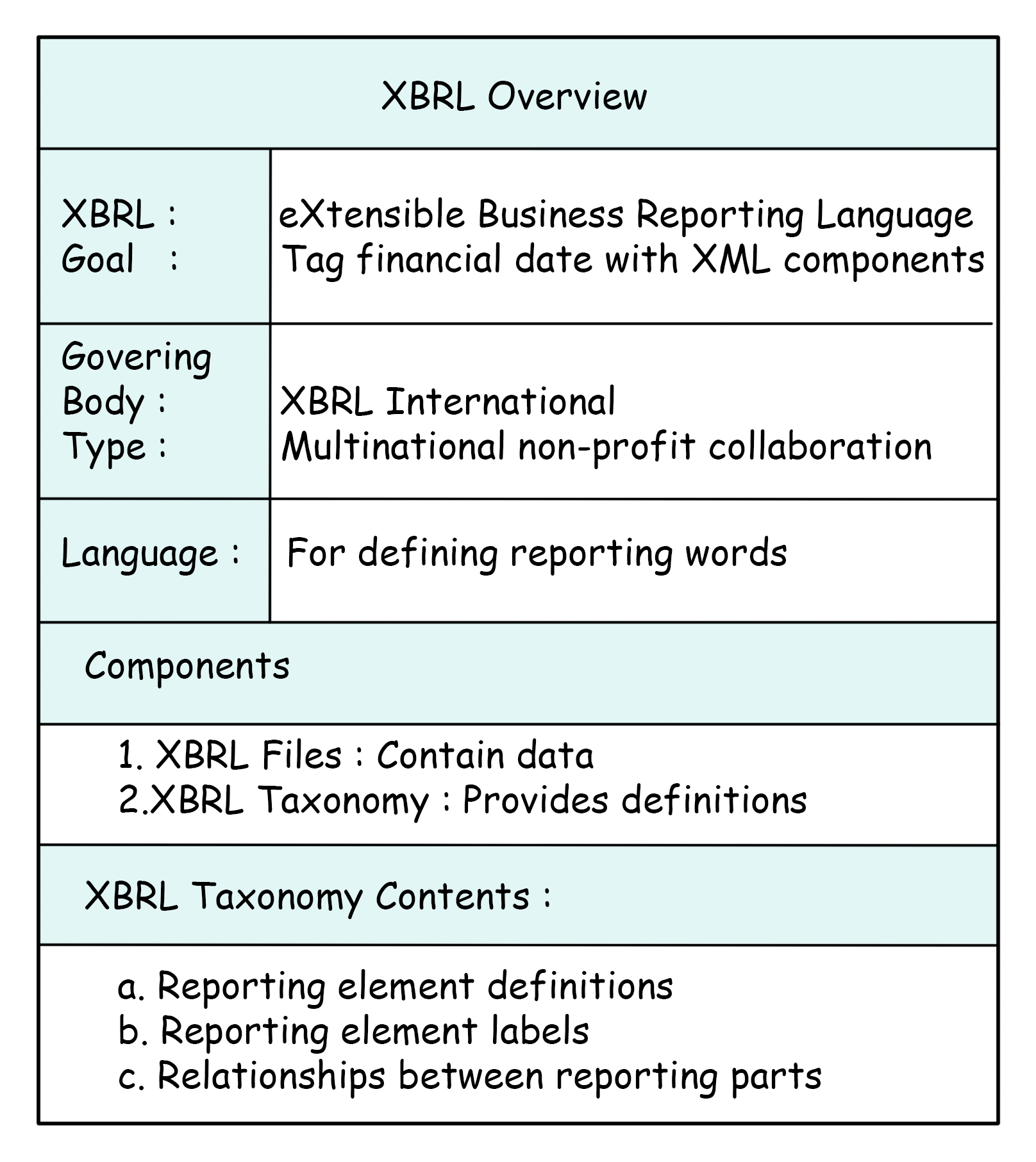
When you submit financial data using XBRL, you also need to include something called a "taxonomy."
This is like a set of instructions that helps machines understand what each piece of data means. To do this, you have to load all the different files that are part of the taxonomy, like XML Schemas and linkbases.XBRL technology has a bunch of different parts, but the most important one is called XBRL v2.1.
If you're interested, you can check it out here: http://www.xbrl.org/Specification/XBRL-2.1/REC-2003-12-31/XBRL-2.1-REC-2003-12-31+corrected-errata-2013-02-20.html
There are also other parts that work together with XBRL v2.1, which you can find listed on this page:
https://specifications.xbrl.org/specifications.html.
To help you understand how everything fits together, there's a picture below that shows all the different parts of XBRL technology.
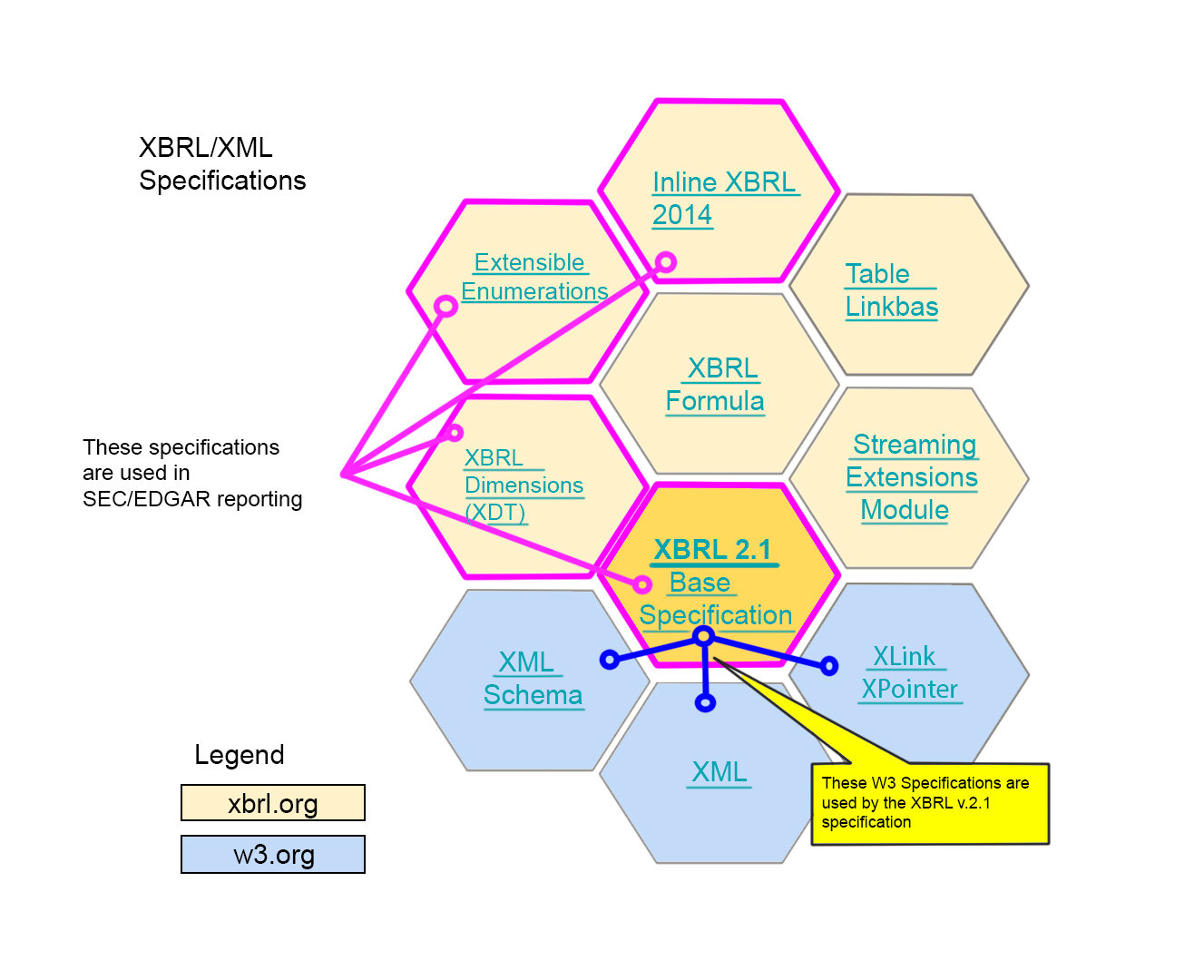
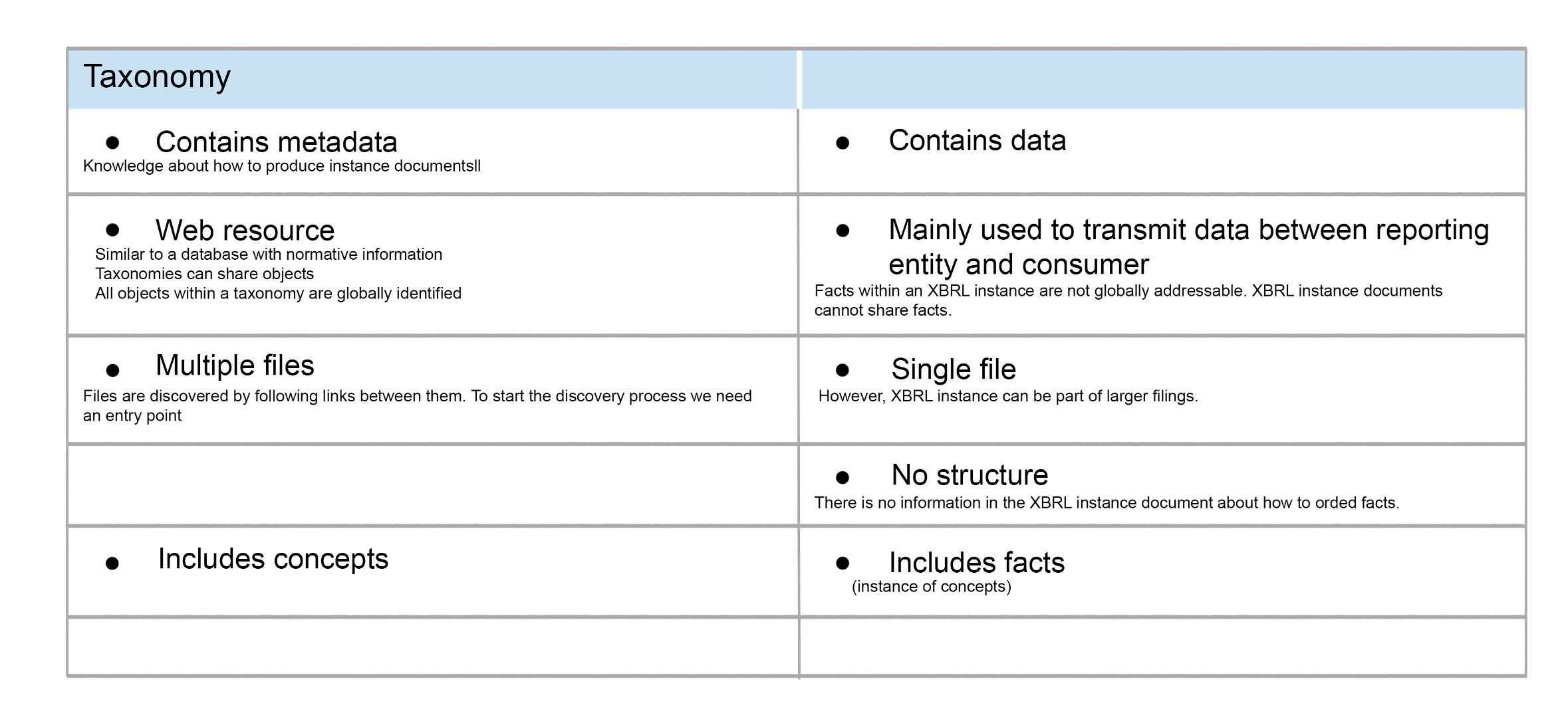
An XBRL instance document is like a box that can hold many different facts. It doesn't have any specific order or structure to it. You can put just one fact in it, or you can put in many facts - even millions of them! It's up to the person creating the document to decide how they want to organize it. Sometimes, regulators might have rules about how the document should be organized. For example, in the SEC/EDGAR system, an XBRL instance document can only have information about one company in it.
An XBRL instance is like a big container that holds all the important information that people need to know about a company or organization. This container is made up of lots of small pieces of information, like numbers and words, that are organized in a special way. We call these small pieces of information "facts".
The XBRL instance container is made using a special type of computer language called XML. This helps the computer understand how all the facts are organized inside the container. The container is always identified by a special word, <xbrl>, which tells the computer that it's an XBRL instance.
Taxonomy
A taxonomy is a special kind of dictionary that contains definitions of words and how they are related to each other. But in the case of XBRL, it's a dictionary that contains definitions of business concepts and how they are related to each other. The taxonomy also includes various resources that help make it easier to understand these concepts, like examples and explanations.
Taxonomy Schema
A taxonomy schema is like a rulebook that tells us how to talk about different things when we're using XBRL. It's written in a special language called XML Schema, which helps computers understand the rules. One of the most important parts of the rulebook is the part that explains what different words mean. It's like a big dictionary that tells us what each word means in the context of XBRL.
Discoverable Taxonomy Set (DTS)
A DTS is a collection of special lists and maps that help us understand and report on something. Imagine you have a really big puzzle with lots of different pieces. The taxonomy schema is like a list that tells you the names and descriptions of all the different pieces.
Linkbase
A linkbase is like a map that shows how the different concepts in a taxonomy are related to each other. It's made up of a bunch of special links called "XLINK extended links" that help explain the meaning of the concepts in the taxonomy. It's kind of like how a map shows you how different cities and roads are connected to each other.
Extended Link
An extended link is a special code used in XBRL that helps connect different pieces of information together. Think of it like a special glue that sticks two things together. It helps us understand how different pieces of information related to each other, even if they are in different places.
Arc
Arcs are like special links that connect different concepts or pieces of information together. They help to show how the different parts are related, kind of like how puzzle pieces fit together. Arcs can even connect facts to footnotes, which is pretty cool! Each arc has some information about what it's connecting and how it's related. The most important thing about an arc is its "xlink:arcrole" attribute, which tells you what kind of connection it is. It's like the label on the puzzle piece that tells you where it fits.
Resource
Resources are pieces of information that help explain more about a concept or item. They are like small bits of information that are stored together with other information. These resources are kept in what are called extended links, which are just special sections of an XBRL file.
Reporting Fact / Fact
A fact is like a piece of information that tells you something important. It's used in reports to show a number or a value. But a fact is more than just a number, it also includes other information like who the number is when the number is for, and what kind of measurement is used. All this extra information helps people understand the number better.
Concept
Concepts are like the building blocks of XBRL. They help us describe important things about a business. There are two ways to define a concept: one way is to use special words in an XBRL computer file, and the other way is to give a definition of what the concept means in real life.
Context
A context is a container that holds important information about a fact, like who or what the fact is about and when it happened. We can use the same context for multiple facts that are related to each other, so we don't have to keep repeating the same information over and over again.
Unit
This tells you what kind of measurement is used for a fact. For instance, it could be in British pounds (GBP), United States dollars (USD), or other currencies.
Reporting Entity
This is like a name tag for a company or organization that is reporting information. It's called a "classification code" and it helps a specific regulator, like SEC/EDGAR, to identify the company. In SEC/EDGAR, this code is called the CIK code.
Period
When we talk about financial information, we often use these concepts to say when a number was true or for how long it was true. For example, we might say a company had $100 in profit as of December 31st (an instant), or that they had $100 in profit for the entire year (a duration).
Dimension
Dimensions are like different labels we can put on a fact to describe it in more detail. For example, if we have a fact about sales, we can use the "product" dimension to say which specific product the sales are for. Dimensions help us organize and understand facts better.
Dimension Domain
A domain is like a group of things that a fact can belong to. For example, if we're talking about sales, the product dimension is like a domain of all the different products that the sales numbers can be about. Another example is longitude and latitude, which have a domain of numbers between -180 to +180. Basically, a domain is like a set of possible choices that a fact can belong to.
Explicit Dimension
Explicit dimension is a term used to describe when the names of the members in a set are listed. It's like having a list of all the possible types of pizza toppings or ice cream flavors. In this way, we know exactly what the members of the set are. This type of dimension is created by linking the set of members to the concept that it belongs to.
Typed Dimension
A typed dimension is a type of dimension that has too many members to name them all. It's like when you try to count all the grains of sand on a beach - it's just too many! In the example above, the "Longitude and Latitude" dimensions are typed dimensions because there are too many numbers between -180 and +180 to list them all.
Hypercube
A hypercube is like a big box with many sides. Each side of the box is a different way to measure something, like the length, width, or height of an object. The hypercube helps us organize and understand information by putting it into different categories based on these measurements.
Base Set
A bunch of connections between different things in a computer system. A basic set is a group of connections that have the same name and job.
XBRL v2.1 Specification - This is the main specification for XBRL version 2.1. It provides a standard way of representing financial and accounting information in a machine-readable format.
You can access it at:
XBRL Dimensions 1.0 - This specification provides a way to express information about financial data that can be used to analyze and compare data across different organizations or periods.
You can access it at: http://www.xbrl.org/specification/dimensions/rec-2012-01-25/dimensions-rec-2006-09-18+corrected-errata-2012-01-25-clean.html
Inline XBRL Part 1: Specification 1.1 - This specification provides a way to embed XBRL data directly into HTML documents, making it easier to read and analyze financial data.
You can access it at:
Extensible Enumerations 2.0 - This specification provides a way to define and use lists of values (such as currencies or account codes) in XBRL documents.
You can access it at: https://www.xbrl.org/Specification/extensible-enumerations-2.0/REC-2020-02-12/extensible-enumerations-2.0-REC-2020-02-12.html
W3 Specifications
Extensible Markup Language (XML) 1.0 (Fifth Edition) - This is the main specification for XML version 1.0. It provides a standard way of describing and structuring data in a machine-readable format.
You can access it at: https://www.w3.org/TR/xml/
W3C XML Schema Definition Language (XSD) 1.1 Part 1: Structures - This specification provides a way to define the structure of XML documents and the rules for how they should be validated.
You can access it at https://www.w3.org/TR/xmlschema11-1/
W3C XML Schema Definition Language (XSD) 1.1 Part 2: Datatypes - This specification provides a way to define data types in XML documents and the rules for how they should be validated.
You can access it at https://www.w3.org/TR/xmlschema11-2/
XML Linking Language (XLink) Version 1.1 - This specification provides a way to create links between different parts of an XML document or between multiple XML documents.
You can access it at https://www.w3.org/TR/xlink/
Namespaces in XML 1.0 - This specification provides a way to avoid naming conflicts between elements and attributes in XML documents.
You can access it at https://www.w3.org/TR/xml-names/
These are namespace prefixes and names used in eXtensible Business Reporting Language (XBRL), which is a standard for exchanging business information electronically.
Here's a brief explanation of each:
Each of these namespaces has a specific purpose within the XBRL standard and is used to ensure consistency and interoperability between different XBRL implementations.
You will receive the information that help to do investments.
Note: Check the spam folder if you don't receive an email.
